How Can a Page That’s Blocked for Crawling be Indexed in Google Search?
Search Engines, such as Google, have things called crawlers that are constantly exploring the far corners of the internet with their insatiable hunger for content and sometimes the crawlers index blocked content.

These search crawlers have so many methods to seek out pages and information contained on a website that there could be a variety of reasons for your blocked content to be indexed.
Crawlers will read all the pages they can find through links in your webpages, as well as parsing the content of files such as sitemaps, PDFs, RSS feeds, and more. The mission for crawlers is to consume and index everything they can find so it can be used as a potential search result when someone is ‘Googling’ a topic.
Anyone working on websites professionally can tell you, there are lots of situations when the owner of a website may want to keep unrelated information, like signup forms, privacy policies, copyright notices, etc., from indexing inside the search engines. Due to the number of approaches available, and partly due to the way mobile crawlers work, it is relatively common to find websites that inadvertently have content, which is blocked by robots.txt, indexed and showing in search results.
- 1 Google Indexing Alerts
- 2 Solving Blocked Page Indexing
- 3 Five Ways to Prevent Search Indexing
- 4 Testing Your Solution
- 5 Getting Help
Dealing With Google Indexing Alerts
At Caorda we maintain hundreds of SEO-sensitive websites that are registered inside the Google Search Console (formerly Google Webmaster Tools). This means we deal with a lot of alerts, but in particular, we get puzzling alerts when the Google crawlers notice a page ‘blocked’ for crawling has still been indexed.
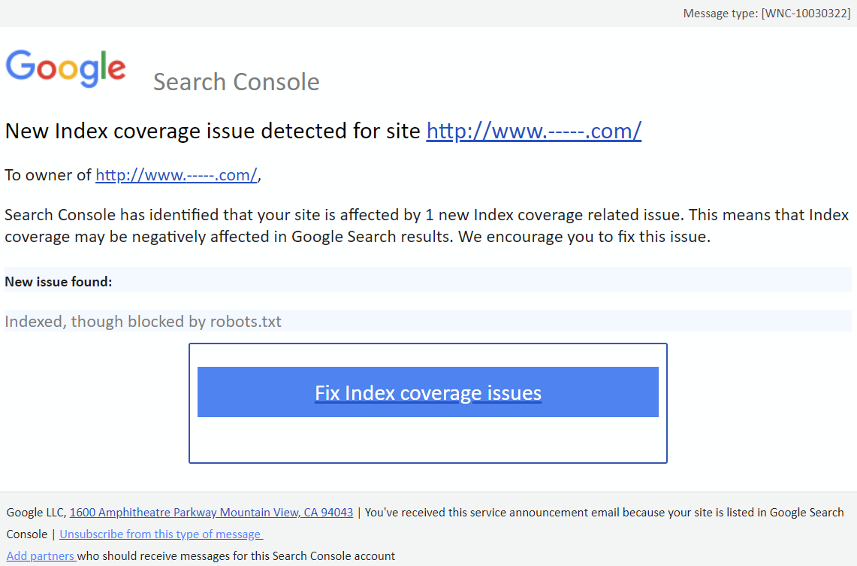
These alerts from Google look spooky, but they can range from ‘who cares?’ to ‘FIX ASAP!’, depending on what URLs are showing up in the search results.
Why Would Google Alert Website Owners?
Google’s search results are still second to none and it’s because they help website owners with alerts to correct issues that are impacting the quality of the search results.
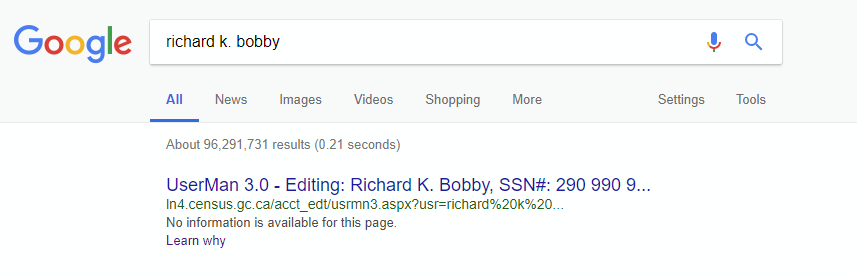
There’s also a small issue of privacy/security when even just the URL is indexed. In the above mockup, we can see what it could look like if internal user editor URLs were getting indexed.
While this is not a real example of a privacy leak, thankfully, most pages that were intentionally blocked from the crawlers were done so for a reason!
Best solutions for blocked pages in the index
The best solution for your indexed pages will depend on how crucially you want to keep the information out of the index. It is a bit like the story of the three bears!
Not Concerned
¯\_(ツ)_/¯
If you don’t actually care that unrelated content has been indexed, you could move on with your day unconcerned about what can be found in Google Search results.
Almost any business website that wants to remain competitive in the search results would care about unwanted indexing.
Slightly Worried
(´・_・`)
Site owners who are mildly annoyed by the indexed data could get by with a simple effort to just de-index the URLs manually and then hope it takes a long time to happen again.
De-indexing is a basic effort that just requires Google Search Console access, which most site owners already have setup.
Serious Panic
(╯°□°)╯︵ ┻━┻
When really sensitive data is indexed, that’s when you will want to start crawling your domains looking for every link to the content that shouldn’t be indexed.
For each link found, make sure there’s a rel="nofollow" attribute setting on the links and/or one of the suggestions below to prevent the entire page from crawling.
This ‘nofollow’ attribute will help tell crawlers to skip each of the links it is applied to and this will help prevent future re-indexes.
5 Ways to Prevent Search Indexing
Without using the robots.txt (which should still be used), there are some other ways we can tell Google (and other crawlers) to skip specific content or entire websites.
No-Index Meta Tag
Setting a “no-index” meta tag is an easy page-wide solution recommended by Google that is explained in detail on the official robots meta tag documentation page directly from the Developers.
<meta name="robots" content="noindex" />
The no-index meta tag can fail to prevent indexing, just like the robots.txt effort, but it is a valid directive, and multiple search engines support it.
We do advise Caorda clients to ensure the no-index tag has been applied to any pages with sensitive content.
Only Block Search Snippets
Blocking page content from showing up in a snippet can be accomplished using the data-nosnippet attribute on the parent element.
<span>This CAN be used for a snippet.</span>
<span data-nosnippet>This is NOT used for a snippet.</span>
<span data-nosnippet="true">This is <em>also</em> ignored for snippets.</span>
Anything with the data-nosnippet attribute will be skipped for snippet inclusion, it does not matter if the attribute has a value or not.
Googleon/Googleoff
Back when organizations could still get a physical Google Search Appliance, there were googleoff and googleon tags you could use mid-page to turn temporarily indexing off or on.
<!--googleoff: index-->
<span>This element would be ignored by a Google Search Appliance.</span>
<!--googleon: index-->
These days it is better to no-index the entire page as it would be very tricky to hide a portion of a page from the Google mobile crawlers since they execute javascript and render CSS.
Header Modifications
If you have a VPS or a dedicated server that hosts a copy of your website or staging ground, you could request a server-side update to modify all response headers with a directive to prevent indexing.
Header set X-Robots-Tag "noindex, nofollow"
The above code example would be added to a host entry inside the httpd.conf for an Apache HTTP server.
Adding the X-Robots declaration to a specific host entry means just that website is blocked from crawling, and other hosts detailed in the configuration file will remain unchanged.
Timed Expiry
Need to make sure something is not indexed after a specific date? This code example allows us to specify when Google should start to ignore/de-index content.
<meta name="googlebot" content="unavailable_after: 15-Jul-2021 8:00:00 PST" />
The above example would tell Google to de-index the page it is found on, but only after reaching the specified date.
Testing Your Solution
Technically you shouldn’t be able to test this sort of bizarre error, because a page in the robots.txt, or marked ‘noindex‘, or with only ‘nofollow‘ links, really shouldn’t wind up indexed.
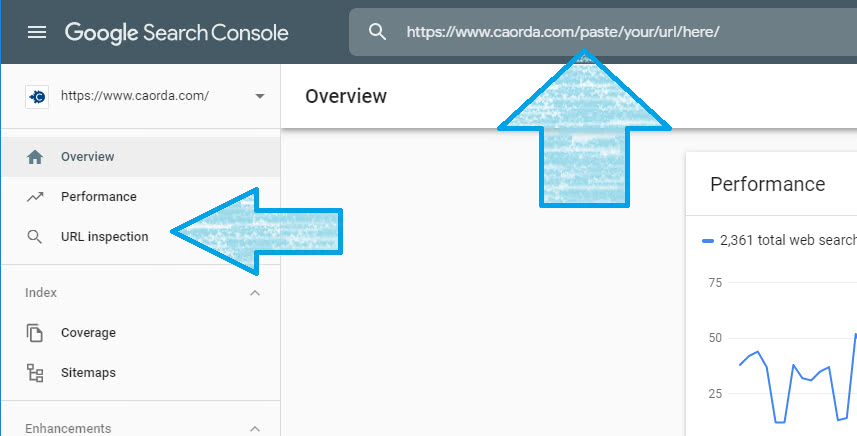
If you have checked all the listed items the only additional test you can do is try a crawl with the URL inspection tool in the Google Search Console as pictured above.
Here to Help!
If all else fails and you just want a Caorda staff member to deal with your alerts, we’ve got search experts who are comfortable with these sorts of indexing-related challenges.
Why not let Caorda leverage our extensive experience’ness to quickly betterize your marketing & website headaches?